February 20, 2026 · 8 min read
Designing and Building a Neo4j Knowledge Graph from Relational Data
How I modeled a Chinook-style music dataset as a property graph, loaded it in the right dependency order, and validated it with Cypher queries.
Peter Mangoro
I treated this assignment as my first serious graph engineering exercise: take a relational dataset, redesign it for graph traversal, and prove the model answers real questions.
Live demo: Chinook Music Knowledge Graph — explore the property graph built from relational CSV data with Cypher queries.
Assignment Focus
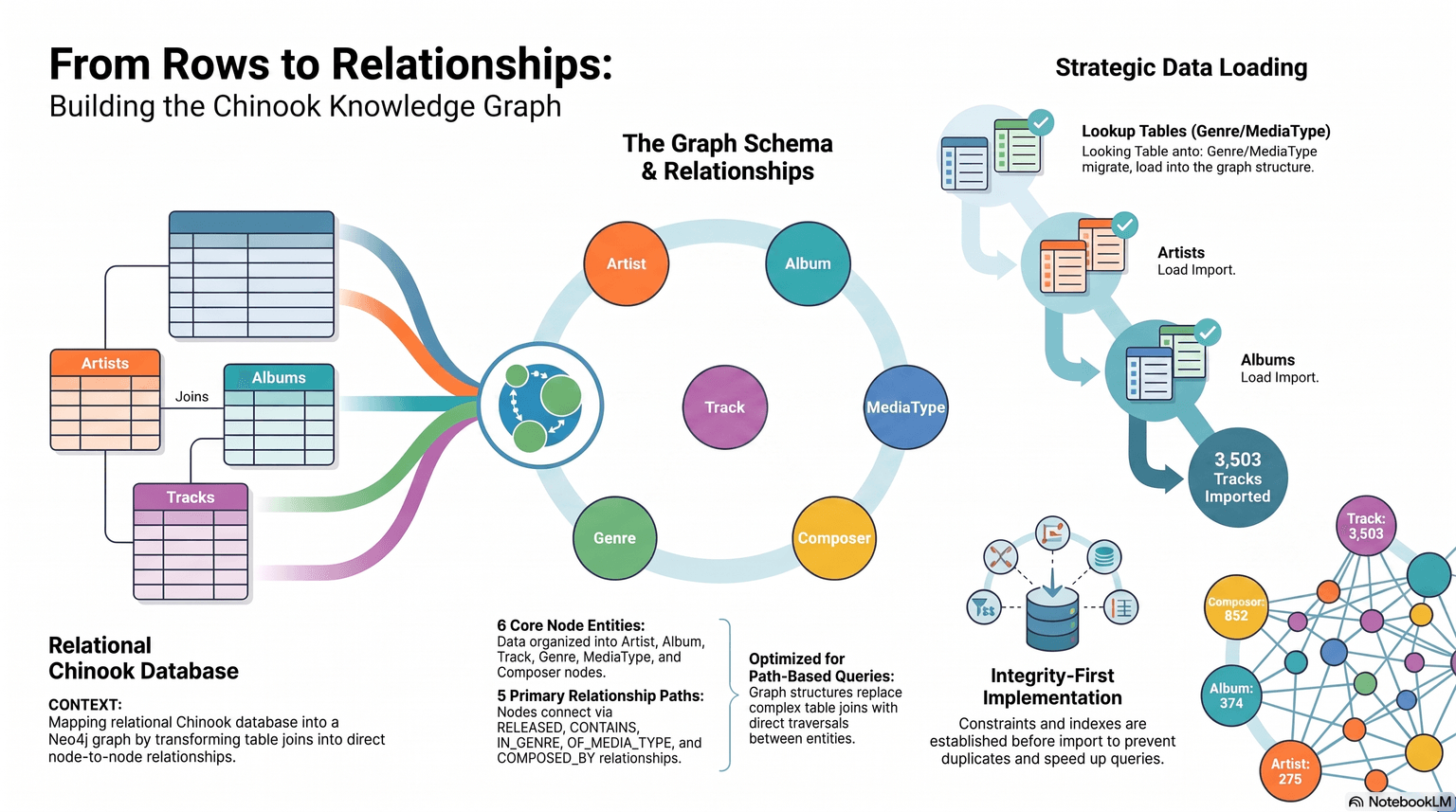
The core task was to move Chinook-style CSV data into Neo4j and model the domain with meaningful nodes and relationships:
- Nodes:
Artist,Album,Track,Genre,MediaType,Composer - Relationships: release, containment, genre/media typing, and composition links
I also had to ensure the database stayed clean and repeatable across reruns.
What I Built
I implemented an ingestion sequence that respected entity dependencies and used MERGE plus constraints for idempotency:
- Created uniqueness constraints before loading
- Loaded reference entities first, then dependent entities
- Added relationship creation in a separate pass
- Promoted composer from a raw track property into first-class
Composernodes
That shift made traversal and composer-level analysis much clearer than string-only storage.
Key Findings
- Load order is everything in graph ingestion: loading dependent entities too early created avoidable misses.
- Constraint-first design prevented duplicate node growth during retries.
- Small data-quality issues (null composers, quoted commas, case mismatches) had outsized effects on query results.
- Targeted indexes improved query responsiveness for filtered lookups by names and titles.
Lessons Learned
The biggest lesson was that graph projects are won or lost in modeling decisions made before writing many queries. Once labels, IDs, and relationships were stable, the assignment became straightforward and repeatable.
I also learned that “works once” is not enough. Re-runnability and correctness under re-ingest are part of the deliverable.
Skills I Gained
- Graph schema design for domain translation (relational -> property graph)
- Practical Cypher ingestion patterns (
LOAD CSV,MERGE, relationship creation) - Constraint and index strategy for correctness and performance
- Debugging ingestion edge cases in real CSV data
Artifacts
- Notebook: P_Mangoro_C1_assn.ipynb
Building a Hybrid Movie Recommender with Neo4j and Graph Data Science
How we built a graph-based movie recommendation system by combining collaborative signals, content relationships, and GDS algorithms.
Developing a GraphRAG Research Chatbot with Neo4j
How I built a GraphRAG-style research assistant that combines Neo4j graph retrieval, vector search, and grounded LLM answers with citations.